Df <- ListForDf %>% as.data.frame() %>%
pivot_longer(everything()) %>%
mutate(name=str_remove(name,"APIName."),value=value) %>%
inner_join(tabmaps,by=c("name"="ValueNames")) %>%
select(Type,Categories,SubCategories,name,InputName,value) %>%
rename(ValueNames=name,Value=value)
Df$Value <- as.numeric(Df$Value)
return(Df)What’s Wrong with Data Science No-Code Tools?
Strategy
Learn why data science no-code tools cause more problems than they solve
Hint: It’s not that they don’t work
Within the various data science fields (business intelligence, MLOps, statistics), there’s an ever growing list of “no-code” tools. These tools allow you to accomplish many things that previously required a programming language, such as R or Python and a programmer who knows how to use them.
Right now, no-code tools are dominating business intelligence and I see many more creeping into other areas of data science.
Is there something wrong with this trend? There are four problems I see, including:
No-code skills don’t transfer between tools
No-code tools require hacky workarounds for exception use-cases
Expert no-code users are capable of learning to program
It’s faster to type a script than to drag-and-drop one
What is No-Code?
When we talk about no-code and code-based solutions, we’re really talking about a spectrum between coding and zero-coding. There is no tool that’s 100% no-code. Conversely, programmers still rely heavily on user interfaces to improve their own workflows.
So when I call something a “no-code” tool, I mean that it falls more to the left on the spectrum below. A “code-based” solution falls more to the right. And there are many great tools that fall in-between, which are called “low-code.”

Reason #1: No-Code Skills Are Non-Transferable
The biggest problem with no-code tools is that the skills developed to use them are not transferable between tasks, which limits data analysts from cross-functional work.
Let me explain why that’s important.
It’s common for multi-person analytics teams to face bottlenecks with project requests. In my experience, it’s because individual contributors are only prepared to work on part of the data pipeline.
For example, one employee (an ETL developer) builds the database tables, a second employee (a report developer) builds the dashboard, and then a third employee (a data analyst) conducts the analysis. (See this visualized below.)
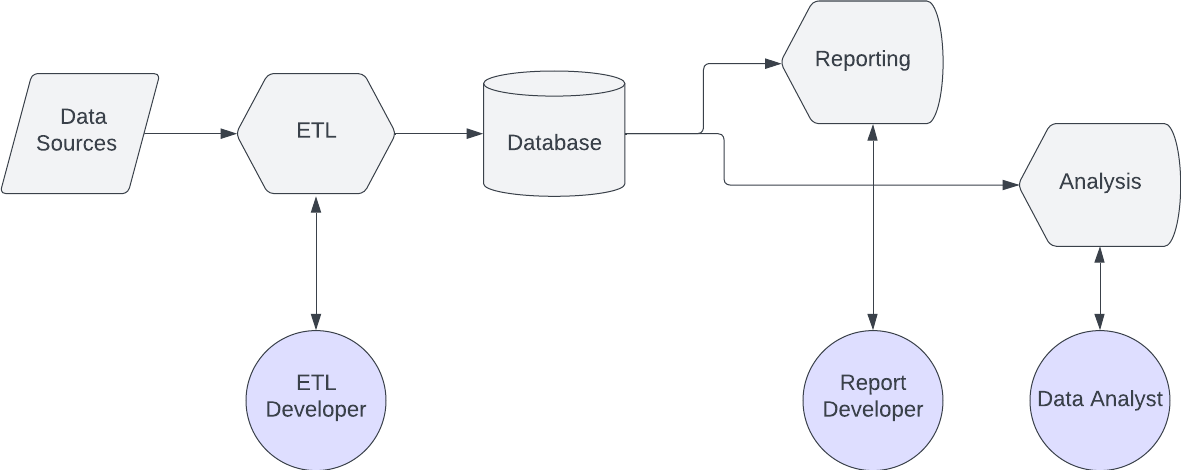
Unfortunately, this means that the report developer and the analyst can’t build anything until the ETL developer builds the data set for them. That inevitably leads to long wait times for downstream data workers.
A team staffed with cross-functional data scientists won’t have this problem. The person who builds the report can build the data engineering to support it.
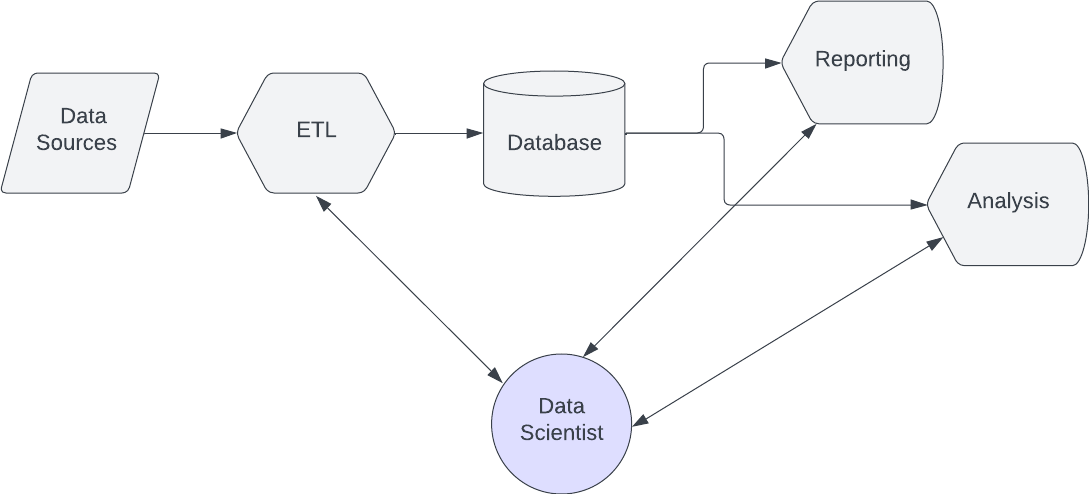
In addition to reducing bottlenecks, a cross-functional data scientist also reduces the risk of miscommunication and errors that inevitably result when more people’s hands touch the same project.
What does this have to do with no-code tools?
Well, it’s harder for no-code users to become cross-functional. Let’s say our data team needs to build ETL processes, build reporting, and build predictive modeling – we’d need 2-3 tools.
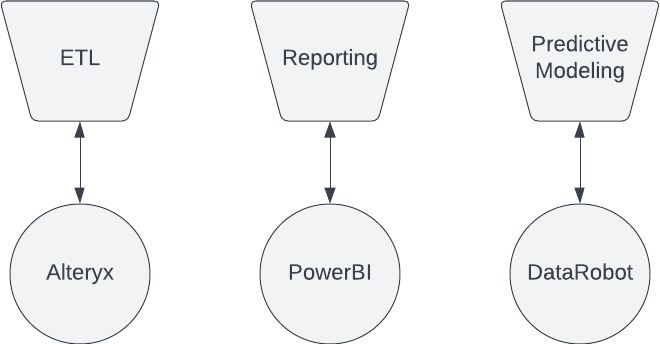
It’s possible that an analyst can learn those three tools, but it requires a greater investment of time to become proficient in all three. Many teams don’t bother to wait around for the analyst to get there. They’ll simply hire three specialists, which creates the bottleneck I described earlier.
A single data analyst who knows R or Python could accomplish all three tasks:
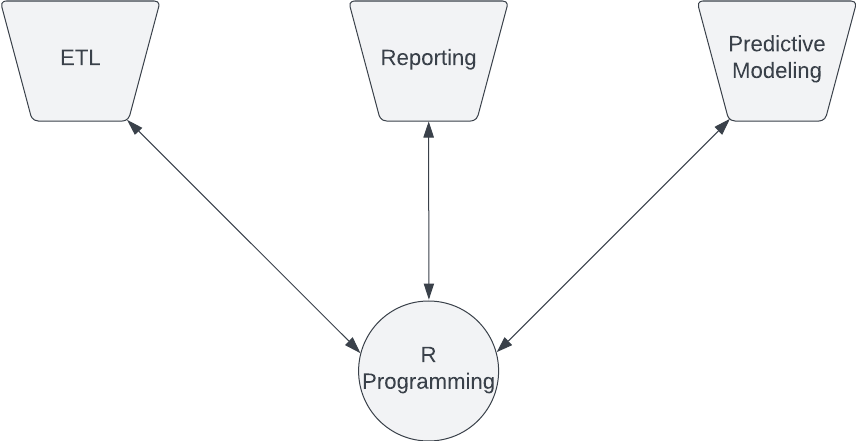
Granted, there is still a learning curve for an analyst to apply R or Python to these three areas, but the skills are transferable. Learning the tidyverse set of R packages is handy for any data strategy. It’s harder to take what you learn in Alteryx and apply it to, say, PowerBI.
This is important because many analytics teams find themselves stuck in the “reporting trap,” where their entire focus becomes generating new dashboards and maintaining existing dashboards, instead of using cross-functional expertise to add value via analysis and predictive analytics.
There are many reasons for this reporting trap, but a big one is that the people on the analytics team only know reporting tools. When you only know one tool, it’s harder to see other opportunities to add value. It’s the old cliche that “to the man with a hammer, the world looks like a nail.”
Reason #2: No-Code Requires Hacky Workarounds
Another big problem with no-code tools is the limit to what they can do. A salesperson loves to show, with a few drag-and-drops, how you have “replaced” the need for a programmer.
Well, that’s true for that one task. However, the advantage of programming isn’t that it accomplishes routine tasks.
It’s the exceptions that matter.
In the 1990s, a joke about Visual Basic (another no-code tool) was that it made 95% of the job easier and 5% of the job impossible. No-code data science tools have the same problem.
Any data analytics team with consistent work will inevitably come across requirements that the no-code designers didn’t anticipate. That forces the data analyst to create a “hack” to circumvent the limitation.
A “hack” means applying a functionality within the no-code tool in a way that wasn’t intended. I’ve met many power users of no-code tools who take pride in their creative workarounds with these no-code tools. But in the process, they have (ironically) revealed the big limitation to the software.
The problem is that the hack is usually… well, hacky. It usually requires additional workarounds and inconveniences for the end-user or the analytics team that has to maintain the solution.
Code-based solutions don’t have hacks. If you come across a unique use-case, you simply write a new script or download a new package someone else wrote. That gives the analyst more flexibility in the long-run.
Plus, the routine tasks that those no-code tools promised to automate can be automated with coding anyways. Programmers have a steady stream of reliable functions and scripts to handle the drudgery that those no-code tools are built to handle.
Reason #3: A No-Code Expert Can Learn to Program
I believe many executives invest in no-code solutions because they assume that people who are not smart enough to learn programming will find no-code easier to learn. That would theoretically increase the talent pool of developers, even if that comes at the expense of flexibility with custom solutions.
But there’s a problem with this line of thinking. Data work, regardless of the tool employed, requires a high level of abstract thinking. There is no drag-and-drop tool on the market that will replace that requirement.
And any data analyst that demonstrates that abstract thinking can learn to code.
For example, a data analyst who’d want to calculate the total revenue per location with the tables below would follow largely the same steps with both a no-code tool and a programming language:
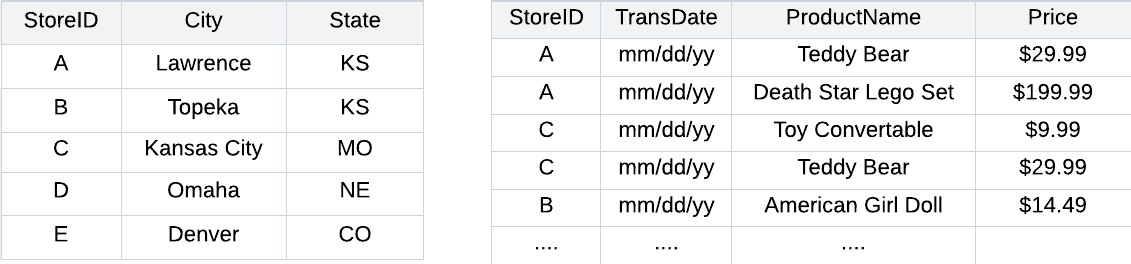
What that means is that both methods require the same level of aptitude. So if you believe you’re gaining greater access to talent with no-code tools at the expense of a programming language’s more expansive functionality, you’re not. You’re merely limiting the analysts you do hire from doing more for you.
Reason #4: Typing is Faster Than Drag-and-Drop
A big reason people say no-code tools are better is that “it’s quicker.” Sure, there are those exceptions that are hard to workaround. Sure, the skills are not as easy to transfer. But at least it’s faster!
But is it really faster?
I can type faster than I can drag-and-drop. A few months ago, I was forced to use Alteryx for a company that wanted that as their ETL tool. It took FOREVER to do what I could do in R with a few lines of code.
For example, this R script took me half the time to write, run, and verify than it would have with Alteryx:
The only trade off is the learning curve. It’ll take you longer to learn to program, but not that much longer. And like I said for reason #1, the skills will transfer to the other areas of data work, making you a cross-functional analyst.
Last Point: No-Code Tools Are for Self-Service
No-code tools have their place in the business world, but should be limited to the end of the data pipeline.
Enterprise solutions should rely on programming skills, but no-code tools can empower users within non-data teams to conduct their own analysis – i.e., a self-service model.
On most non-data teams, there is one person who wants to look into the data themselves. They want to answer business questions that don’t require highly robust solutions with R or Python. That’s the person that needs a no-code tool – the “citizen data scientist.”